Analysing the music I listen to
Posted on Tue 18 April 2017 in Analysis
I’ve been tracking the music I listen to since 2012 through last.fm. They offer a free account and you can install “scrobbler” plugins on different systems used to listen to music to allow you to track the music you listen to. Spotify natively supports last.fm scrobbling too and there are scrobblers that work well with Android devices too (I suspect the same is also true for iOS, but I don’t have first hand experience of it).
Last.fm offer some summary stats, and they can be quite interesting to look at but I felt like a lot more could be done with the data collected, so I decided to analyse the data myself.
The data for the analysis was collected using the last.fm API and analysed using Python in Jupyter Notebooks. The analysis is heavily inspired by this blog post from Geoff Boeing. In fact, a lot of the analysis builds on top of work he has done. The code used for the analysis can be found in the form of Jupyter notebooks over here. The analysis can be easily run using your own last.fm data. All you need is an API key for last.fm.
The data analysed contains 13,446 scrobbles containing 3,908 unique tracks and 522 unique artists. The data analysed is mainly from last.fm, but some additional data about artists, albums and tracks was obtained from musicbrainz.
Let’s start the analysis with some of the usual suspects… Here are the most played artists, albums and tracks in my music history.
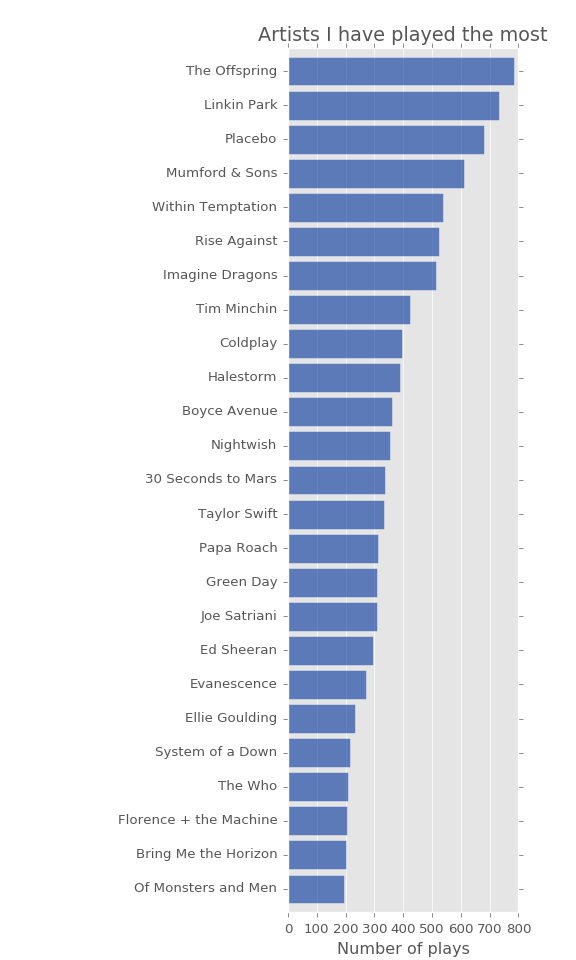
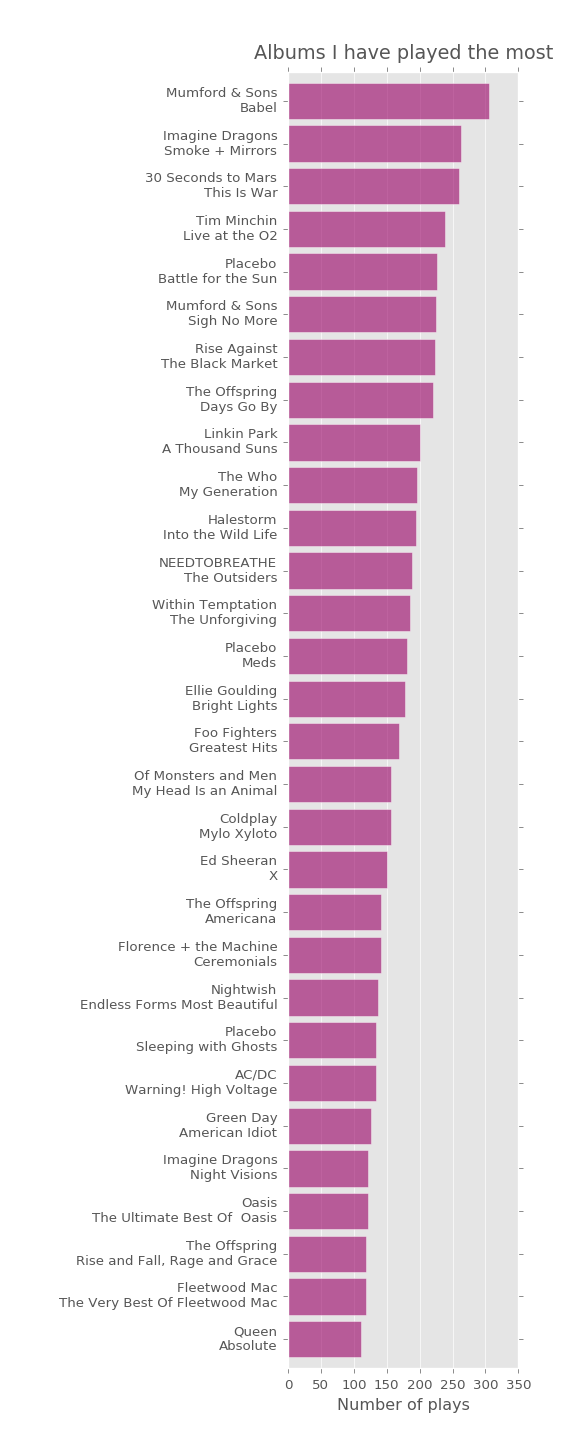
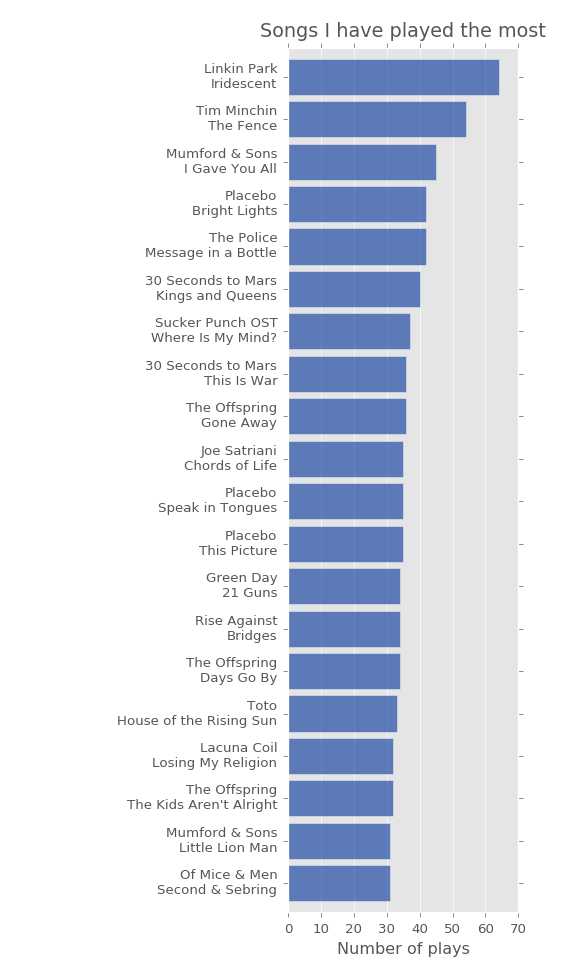
All of the above lists are indicative of my taste in music (or lack thereof, depending on your perspective!), but another interesting aspect to consider is the level of breadth of exploration for each artist i.e. how many unique different tracks from the artist I’ve listended to.
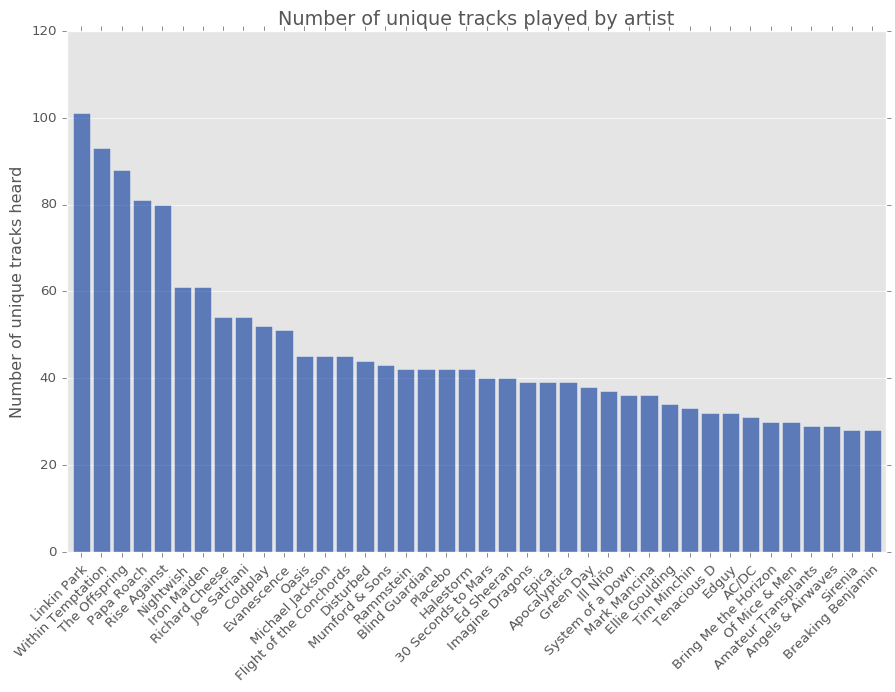
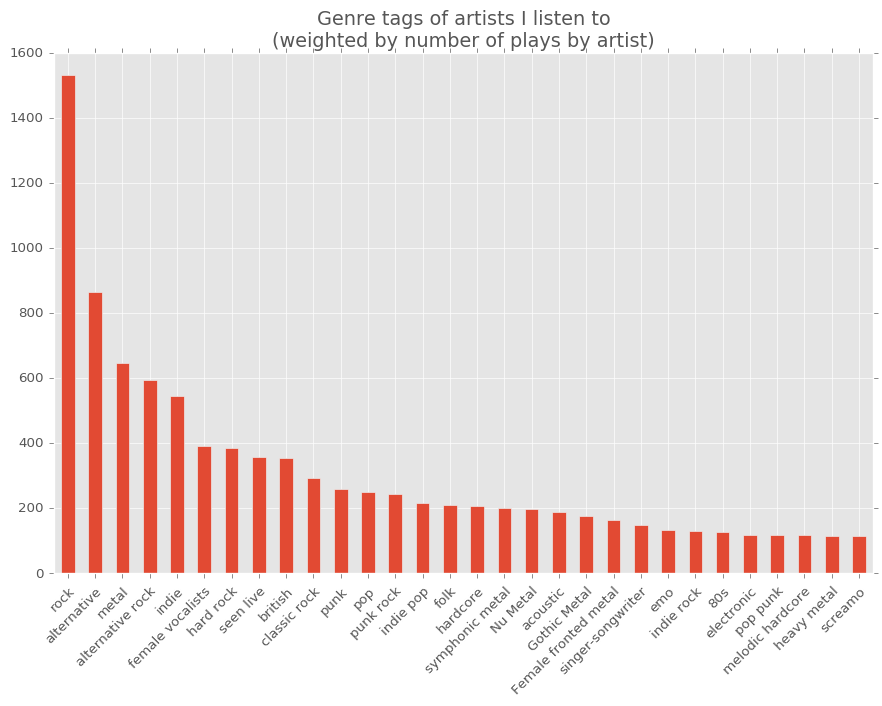
The genre descriptions on last fm for the artists I listen to can also be a useful indicator of the genre distribution of the music I listen to.
…as can the year of release of the tracks I listen to.
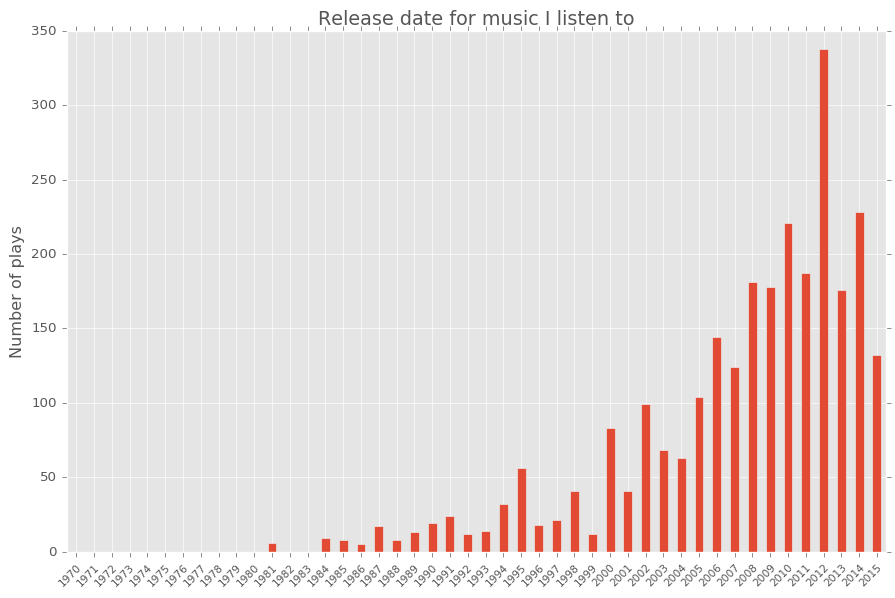
This suggests that most of the music I listen to was made after I was born! It’s worth noting, however, that there the year of release is not available for all tracks in my music history. Some of the data is missing for the more recent years (which is why the plot stops at 2015) and some of the data is also missing for some older tracks in my music played dataset (e.g. The Who and The Beatles), so it is difficult to gauge just how skewed the music I listen to is to music made in the last 3 decades.
Most of the analysis above explores the music I tend to listen to but not how/when I tend to listen to it. I think a lot can be leart about oneself by examining behavioural patterns that aren’t often examined, so below is some examination of patterns in how I listen to music.
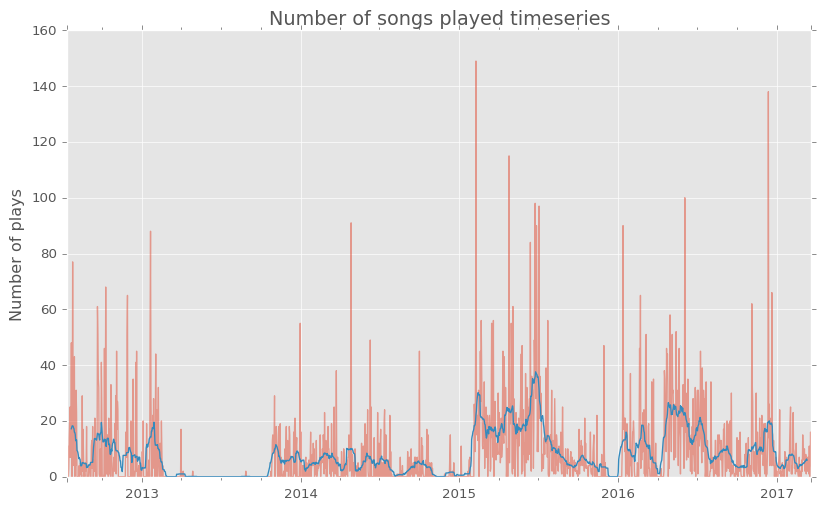
We can look at how the amount of music I listen to has evolved over time.
And look at relative play counts in a calendar view to obtain an intuitive sense for how much daily variation exists.

The breakdown of how much music I listen to by day of week and hour can also be very informative.
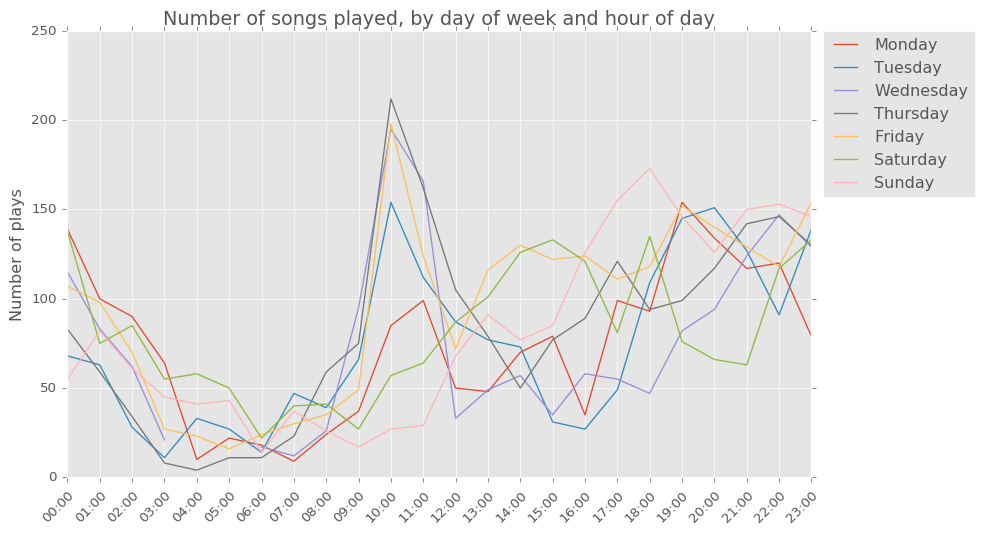
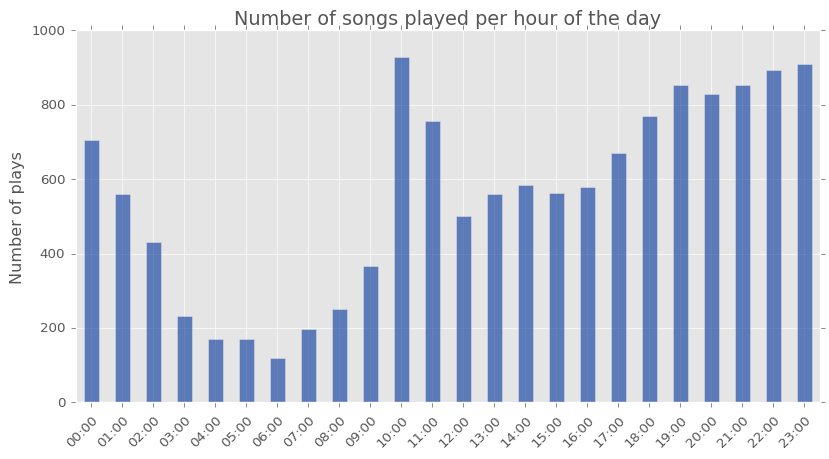
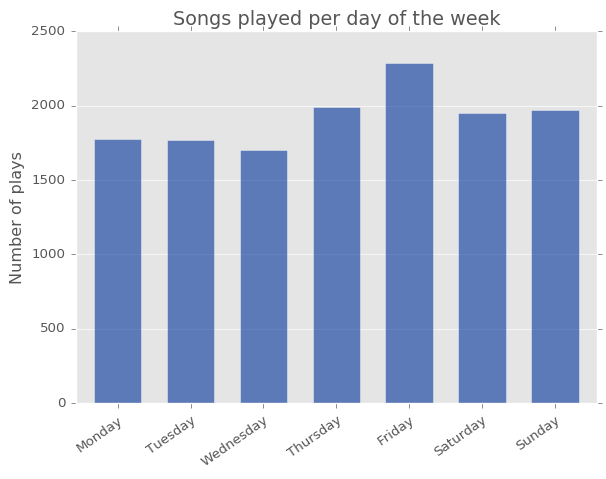
There’s aspects of my lifestyle visible in the plots above. I listen to music a lot around 10 am on weekdays (on my commute to work) and have a fairly erratic sleeping pattern. There isn’t a day of week and time of day during which I haven’t, at some point, been listening to music!
Observing patterns in when I listen to new artists can also be insightful…
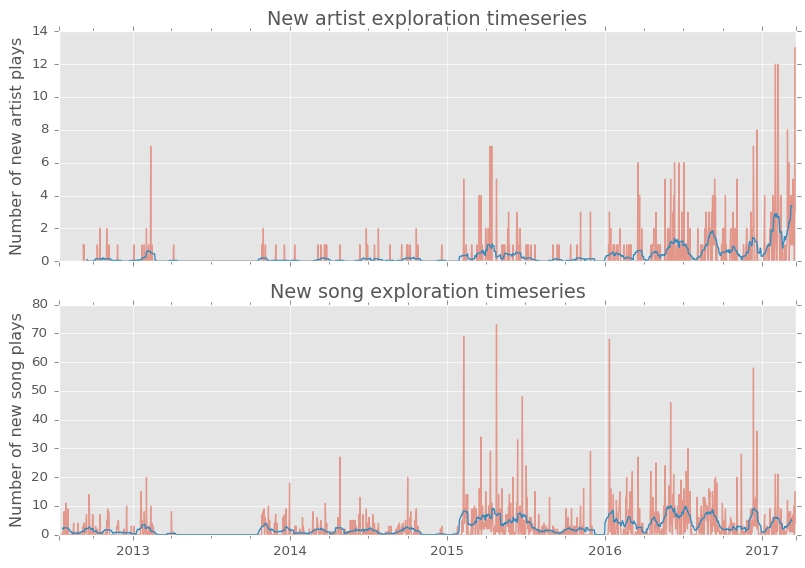
…as can observing when I listen to my most played artists.
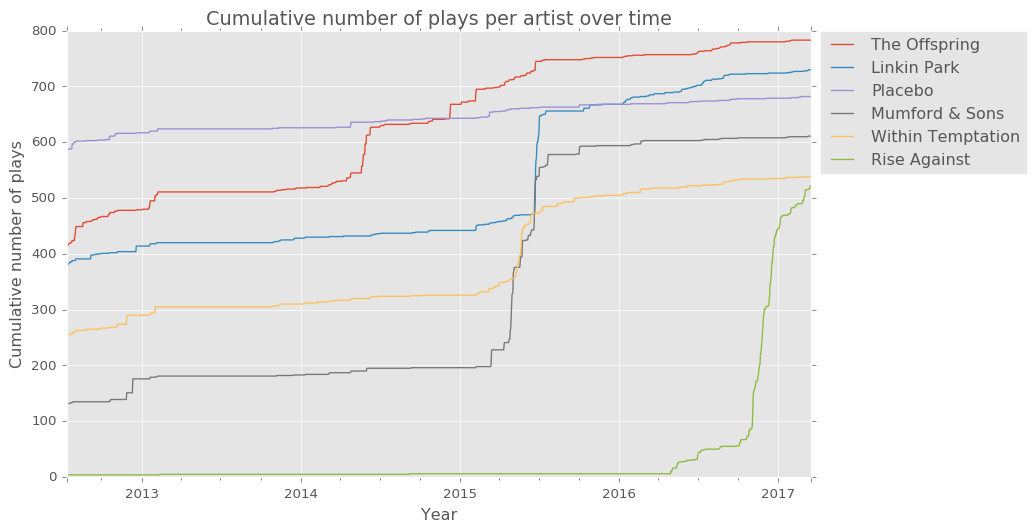
I’m clearly prone to binge listening to my favourite artists. I can listen to 300 or 400 songs from a single band in a span of a couple of weeks. Given the nature of music and how it’s released in albums, it lends itself naturally to music from a given artist being heard in groups of around 12-15 tracks, but my music history suggests that I have a habit of binge listening to artists beyond the scope of what can be reasonably explained by listening to one or even two albums from the band in a couple of weeks.
There’s a lot more that can be done with this data, and I may return to it in the future, but I’ve found analysing my music listnening history very interesting and more insightful than I was expecting.
If you have any other ideas about what might be interesting to do with this dataset, let me know in the comments. The Jupyter notebook that was used to generate all the plots in this blog post can be found here.